Wmatrix tutorials (for version 5)
Step by step instructions using a case study of the linguistic analysis of Political Party Manifestos for the UK General Elections (updated November 2022)
This document describes the method, using the
Wmatrix tool, to carry out a comparison and corpus analysis of the Liberal Democrat and
Labour Party Manifestos for the 2005 General Election. Tutorials A, B and C describe the steps required to
collect, prepare, annotate and analyse the two documents.
For more advanced users, tutorial D shows details of further analyses that can be performed
and tutorial E introduces the methods that you can use to alter the way that Wmatrix
semantically tags the text.
Tutorial F describes the word collocation and semantic collocation facilities.
Tutorial G provides an overview of metaphor analysis features in Wmatrix.
Further examples of the application to the 2010 general election manifestos can be seen
on Paul's blog.
The plain text versions of the 2010 UK election manifestos can be downloaded for
use in your favourite text analysis software (with thanks to Martin Wynne for editing two of the files).
A similar analysis for the 2015,
2017 and
2019
General Election manifestos has been carried out.
The recent manifesto files are also available on GitHub.
NOTE: If you are using Wmatrix version 6, then please head over to
the completely revised and updated tutorial for version 6.
Tutorial A: data collection and preparation
- This tutorial guides you through how to prepare corpus files for loading into Wmatrix. You can either use the manifesto examples provided here,
or follow similar steps for your own data.
- Note that the set of election manifesto files are available, pre-tagged and pre-analysed, in the new corpus library feature
available from Wmatrix5 onwards. For details on how to use the corpus library, please jump straight to the second half of Tutorial B.
If you'd like to continue to follow the steps to prepare the data yourself, please continue with Tutorial A and then the first half of Tutorial B.
- Locate the two manifestos on the Labour and
LibDem websites, if they are still there. Otherwise use the local copies provided here.
- Accessed on 5th May 2005, Labour provide their manifesto in PDF at:
http://www.labour.org.uk/fileadmin/manifesto_13042005_a3/pdf/manifesto.pdf
(local copy)
- Using Adobe Reader (or Adobe Acrobat),
save the Labour document as plain text (File Menu -> Save As -> then change the file type to plain text).
Please note that with some versions of the Adobe tools, you will need to manually
remove running heads and bullet points by editing the resulting plain text file. Bullet points
may be converted to the single character 'n'. Running heads may appear in the middle of
some sentences that run over a page break.
- This plain text version still contains some non-ASCII characters. Remove these by
opening the text file in Microsoft Word and saving the file as text with line breaks (File Menu -> Save As -> then change the file type to text with line breaks: in MSWord 2000 onwards).
- The resulting file contains a few remaining non-ASCII characters (e.g. pound sign)
but these can be left in for now (local copy).
- Accessed on 5th May 2005, the Libdems provide a PDF version of their English General Election manifesto at:
http://www.libdems.org.uk/media/documents/policies/manifesto2005.pdf
(local copy)
- Since this file contains multiple columns and the Adobe conversion to text from multiple column format does not always preserve the correct word order, it is preferable to use the text version of the manifesto
in RTF format at:
http://www.libdems.org.uk/media/documents/manifesto05.rtf
(local copy)
- Open the RTF file in Microsoft Word and save the file as text with line breaks (File Menu -> Save As -> then change the file type to text with line breaks: MSWord 2000).
- The resulting file is now ready for use in Wmatrix
(local copy).
- The above steps illustrate the process for these two files. The same steps can be applied to other
PDF, DOC or RTF files in order to convert them to TXT format for Wmatrix.
- If you have a very large number of files that you wish to load into Wmatrix, then they need to be grouped together
in one or a small group of files. Unix, Linux and Mac OSX users can use the 'cat' command to concatenate files.
On Windows, you can use the 'copy' command with a list of files to concatenate them
(see http://en.wikipedia.org/wiki/List_of_DOS_commands#copy).
If you group your files into a smaller number and then load these in to Wmatrix, the resulting folders
can be grouped into one Wmatrix folder using the
'join' option in the advanced user interface.
- When loading any data in to Wmatrix, care should be taken when the file contains angled brackets (< or >).
These can be misinterpreted by Wmatrix as XML tags and some of the text may be left untagged and not counted by Wmatrix.
See the input format guidelines for further instructions on how to
avoid these problems.
- If you wish, you can deliberately force Wmatrix to ignore sections of your text e.g. headers or speaker markers.
In order to do this, enclose this text within angled brackets e.g.
<speaker id="A1">
or
<A>
or
<head content="Any header text here">
would all be ignored by Wmatrix.
Tutorial B: upload to Wmatrix or use the corpus library feature
- Log in to Wmatrix using your existing username and password. From Wmatrix5 onwards, your username is the email address that you used to create your account.
- You can upload files to Wmatrix by clicking on the tag wizard option and using the following steps.
- For the LibDem text file, follow the instructions to name the folder, select the
file on your local disk, and click to upload the data.
- Wait while the tag wizard completes the annotation and frequency counting process. It should take around one minute to complete.
- Repeat the above two steps for the Labour text file.
- The two manifestos are now ready for analysis in Wmatrix.
- If you wish to use the election manifesto corpus files without having to manually upload the data, you can use the Wmatrix corpus library feature, as follows.
- Click on the Library option in the menu.
- You will see a set of folders that are available for you to use from the Wmatrix corpus library.
- Select which folders you want to use, and then click the "Access corpus library folders" button.
- The corpus library folders that you have selected will be linked to your Wmatrix account, and you can now proceed with Tutorial C.
Tutorial C: data analysis (using the simple interface)
- Click on the "My Folders" option to see the Labour and LibDem folders that you
have created using the tag wizard, or linked using the corpus library feature.
- Click on the LibDem folder and view the word list to see words most used in the LibDem manifesto:
'the', 'and', 'to' are most frequent, not surprisingly,
but 'government' is used 84 times, 'tax' 50 times, 'environment' 34 times.
If you are using the advanced interface, the full list
can be saved as a text file by right clicking on the file icon and clicking 'save as'.
Note that some multi-word-expressions are marked
by the system as words joined by underscore characters e.g. red_tape, tuition_fees, public_transport.
- In the same way, you can view word frequencies for the Labour Manifesto
(LibDem full word frequency list
and
Labour full word frequency list).
- Note that using the advanced interface, you can also view frequency lists by
part-of-speech and semantic tag (see Tutorial step D.3).
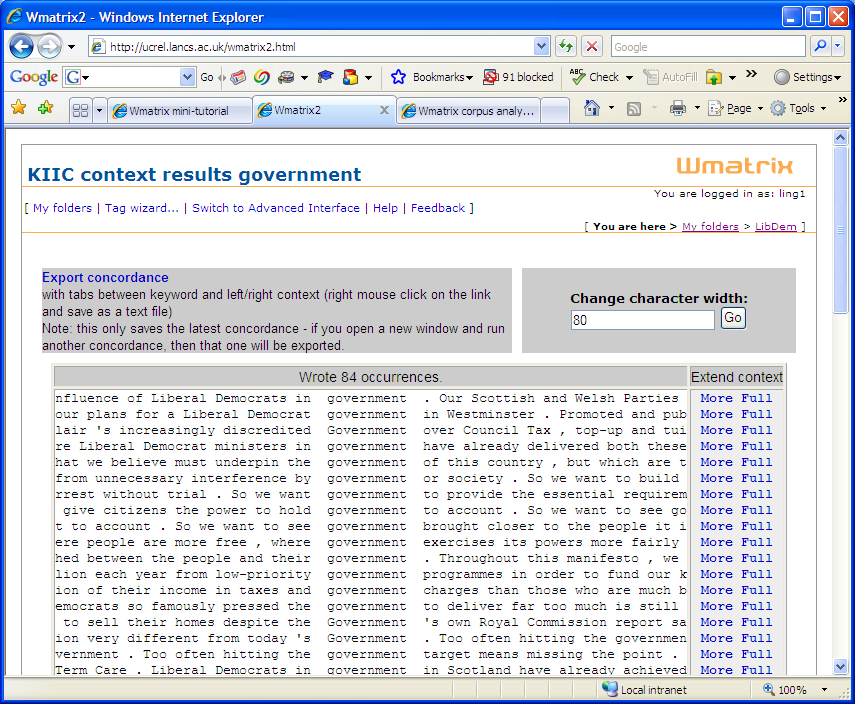
- To see a concordance of a particular word or tag, click on the concordance link alongside
the word or tag in a frequency list.
A sample of a concordance is shown here:
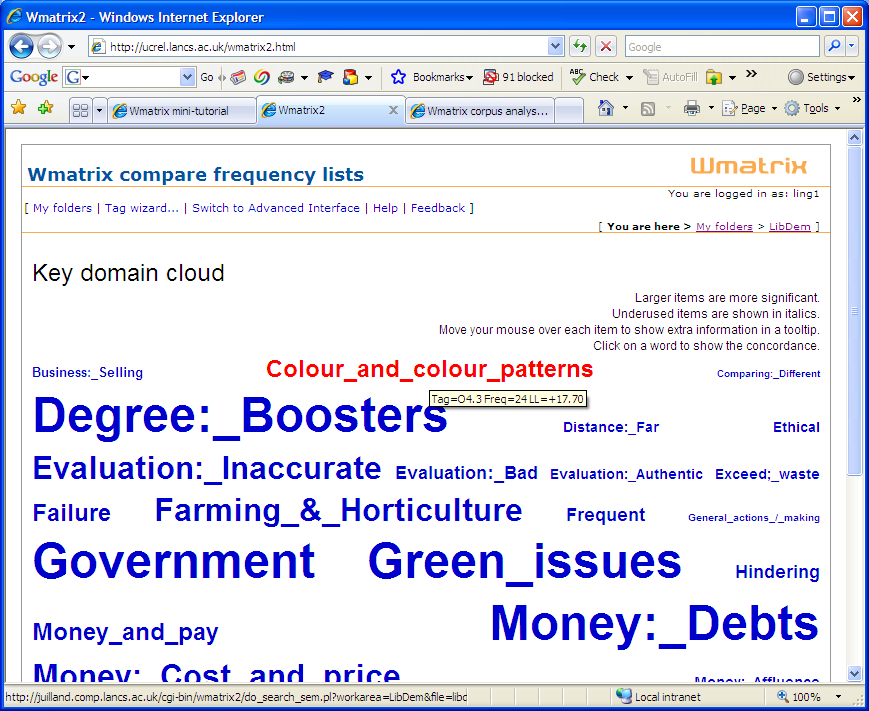
- To compare the LibDem and Labour manifestos using the simple interface, select the Labour Manifesto folder
from the drop down lists under word cloud and tag cloud options. This shows
a visualisation of the items that are significantly more frequent in the LibDem manifesto
than the Labour one. A larger font indicates greater significance.
In the advanced interface, much more information appears alongside the clouds
in table format showing the underlying frequency and log-likelihood information,
see step D.4.
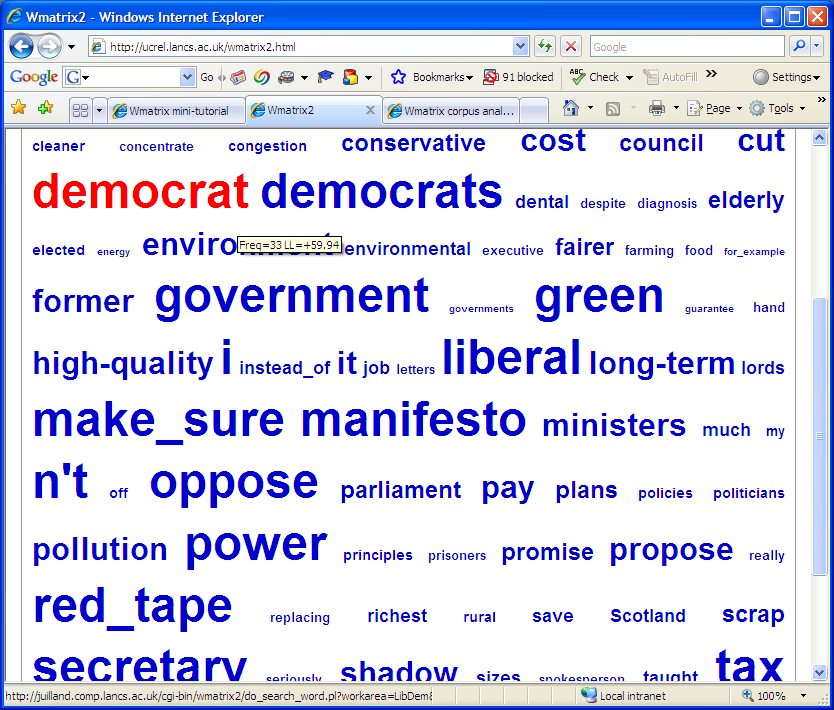
- Concordances can be seen by clicking on the word or tags in the
simple interface. Tooltips, which appear by hovering your mouse over the words
or tags, show frequency and log-likelihood information.
- By default the clouds show overused items in the LibDem manifesto.
If you want to see overused items in the Labour manifesto, you need to change
to the Labour folder (click on My Folders top right and then choose the Labour
folder) and then select the LibDem manifesto in the drop down list.
- Compare the word cloud and the tag cloud for the LibDem versus
Labour comparison. Which features in the text are shown in both word
and tag clouds? Which features only emerge when you use the tag cloud?
Are there any words in the word cloud which cannot be found in the key
semantic tags in the tag cloud?
- So far you've compared the two manifestos directly against each other.
You can also compare one manifesto to a large reference corpus to discover key
words and key semantic categories. For example, if you compare the LibDem manifesto against
the 'BNC Sampler Written' corpus, then items such as "pensioners" and "people" appear as key.
The choice of which reference corpus to use is very important. Experiment with some
of the other standard reference corpora provided in the tool e.g. British English 2006 (BE06)
and American English 2006 (AmE06) to see what differences emerge in the results.
Further details about the reference corpora that are available in Wmatrix can be seen in the help system
by clicking on "Contents" in the Help menu at the top of the screen and then selecting the topic
"Standard reference corpora for key analysis".
- If you repeat these steps for the LibDem 2010 manifesto (compared against the BNC Sampler Written)
and contrast the results at
the word level to the results at the key domains (semantic tags) level then you will
begin to see where some of the results at the key domain level reinforce results at the key words level
e.g. "sustainable" and "climate" appear as key words and "Green issues" appears at the semantic level.
In addition, some further patterns can only be seen at the key semantic level e.g.
"Law and order" appears at the semantic level but is harder to spot at the key words level (other than
with key words lower down the list such as "law" and "prison").
This illustrates the advantage of the key semantic domains approach over the key words approach since
it allows you to spot further items of interest that otherwise do not appear with other techniques.
For more details about this, see the 2008 paper in IJCL:
Rayson, P. (2008). From key words to key semantic domains.
International Journal of Corpus Linguistics. 13:4 pp. 519-549.
DOI: 10.1075/ijcl.13.4.06ray
- If you haven't already done so, you should now switch to the advanced user interface
by going to the top of the Wmatrix screen, clicking on "My folders" and then
click on "switch to advanced interface". Then when you click on any folder,
you will see much more detailed information and many more options for exploring and analysing
the data therein. For more guidance on the advanced interface, please view the
"Advanced Folder Interface" video that appears on the Wmatrix home page.
Tutorial D: Advanced data analysis (tokenisation, MWEs, n-grams and c-grams)
Please note that the n-grams and c-grams features in Wmatrix are currently switched off while a new faster and more powerful n-gram tool is implemented.
- In step C.2 above, we saw that the word frequency list contains some
multiword expressions. Using the advanced interface for Wmatrix, you can
extract the multiword elements marked by the tool and find n-grams and c-grams.
In this part of the tutorial, we will look at some of the advanced features
in Wmatrix which include MWE analysis.
- At the top right of the Wmatrix screen, click on "My folders" and then click on
"switch to advanced interface" (if you haven't already done so by now).
- Select the LibDem Manifesto 2005 folder as before and you will see a more
complicated interface than the simple view.
This lets you see frequency lists of POS tags as well as compare
POS tag profiles just as you did before with word and semantic tag profiles.
Try experimenting with these features to see how the Labour and LibDem
manifestos compare.
- Also, at this point you can familiarise yourself
with which features are the same as in the simple interface:
word frequency is the same, word search is called concordancing in the
advanced interface, and the word clouds views
include much more information in table format.
Some features are new to the advanced interface:
POS tag frequencies, key POS analysis, file format conversion and download.
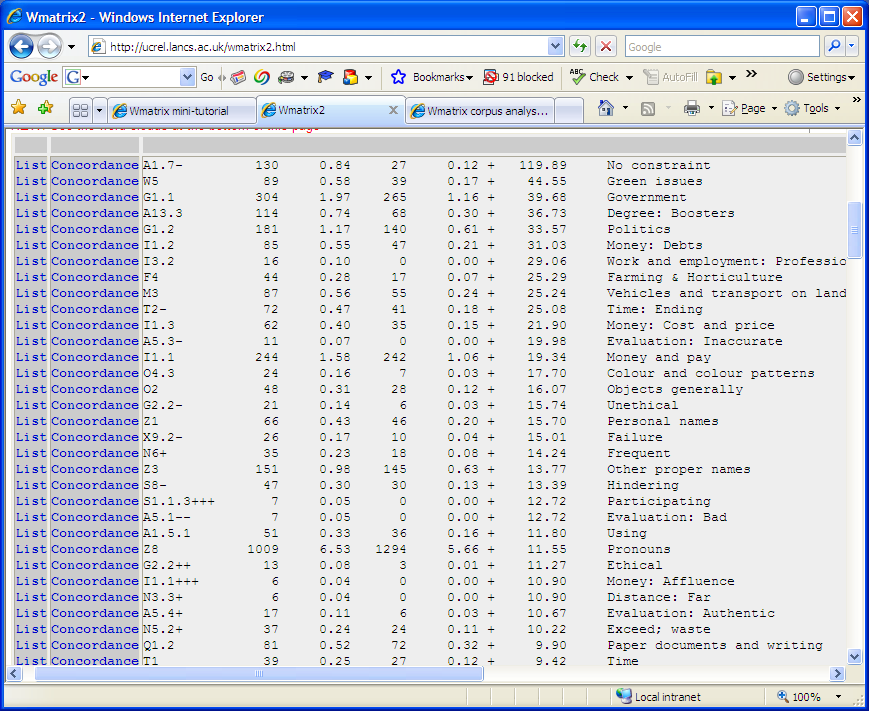
As an example of the more detailed information in the advanced interface,
once you are in the LibDem folder you can select the Labour Manifesto folder
in the 'key analysis' drop down lists at the word, part-of-speech and
semantic level. At the semantic level, the table below is produced.
The keyness table is sorted on the log-likelihood value, resulting in the most significant
differences at the top of the table.
Full word lists for each tag can be seen by clicking on the 'list' links
on the left in the advanced interface.
- In order to see multiword expressions (MWEs), first select the word frequency list
sorted by frequency (top left in the main table in the LibDem folder), then ...
- In the predefined filter drop down list, select multiword expressions and
click 'go'. You should see just the MWEs contained in the word frequency list.
For example, "make_sure"
occurs 22 times, "such_as" 17 times, "red_tape" 13 times. If you click on
any concordance link, these will be shown just as for single word concordances.
- The USAS semantic tagger marks multiword expressions (defined here as a single meaningful unit) and
they are assigned a single semantic tag and counted as one item in the frequency lists.
For further information on how Wmatrix identifies MWEs using
manually defined rules or templates in the USAS dictionaries, you can read
three papers, Piao et al (2003),
Piao et al (2005) and
Rayson et al (2004).
Full references are listed on the USAS website.
It is also worth noting here that the tokenisation principles (i.e. how word boundaries are defined) in Wmatrix
are designed to help annotate and count meaningful linguistic units and chunks.
Wmatrix relies on CLAWS to do its word tokenisation, and contracted forms are split into separate words
to give each part an individual POS tag
(see CLAWS tagging guidelines for more information).
- Another way to identify MWE is using the n-gram technique for counting
recurrent 'n'-words-long patterns in the text.
Note that a 1-gram list is equivalent to a plain word frequency list.
In the advanced interface,
you can see n-grams from 2 words long up to 5 words long from the main interface. These are
found by clicking on the numbers 2, 3, 4, and 5 in the first line of the table
alongside the word frequency lists. If these numbers are not shown, you need
to click on "Make: n-grams (2 to 5) and c-grams" in the bottom right of the main
table and follow the instructions displayed there.
- You can export the n-gram lists as tab-delimited files by clicking
on the link on the top right of the table when viewing the lists.
- Compare the 2-gram and 3-gram lists with the lists of MWEs extracted using
the drop down filter in step D.6 above. There is some overlap e.g. "make_sure" and "such_as".
Other items in the 2-gram list ("we will", "of the") are not included in the MWE list
because they are not identified as semantically tagged units by the USAS tagger.
Further items in the 2-gram list e.g. "liberal democrats" and "liberal democrat"
should appear in the MWE list but do not because they are not listed in the USAS
dictionary. Using the advanced features in "My Tag Wizard" you can add your
own words and MWEs to the lists in the USAS dictionaries contained in Wmatrix
(see tutorial E below). A good way to identify
candidates for adding to your own dictionary in Wmatrix is to use the n-gram lists
to find reccuring items.
- Compare the items listed in the 2, 3, 4 and 5-gram frequency lists. What
items in the 2-gram list are also contained in the patterns shown in the
3-gram list? You should
also find items in the 3-gram list that are part of items in the 4-gram list
and so on with 4 and 5-grams.
- In order to avoid the manual work of identifying overlapping items, you
can use c-grams (collapsed-grams). Click on the letter "C" in the main
LibDem folder. You will see a tree representation. This shows which 4-grams appear
within each 5-gram, which 3-grams are contained within each 4-gram and so on
recursively down the tree. For example, "commission on long term care" contains
"commission on long term" and "on long term care". These in turn contain
"commission on long", "on long term" and "long term care". Finally, the 2-grams
"on long", "commission on" and "term care" are subsets of the preceding 3-grams.
- You can export the c-gram table as a tab-delimited file by clicking
on the link on the top right of the table.
- The c-gram approach is intended to help with filtering shorter length n-gram lists to
find more useful n-gram units that might be sensible chunks for linguistic
analysis. This is a new feature in Wmatrix and feedback is most welcome!
Tutorial E: Extending the Wmatrix dictionaries
-
As we saw in step D.10 above, there are some MWE items that you
might wish to add to the Wmatrix dictionaries since they are not
tagged in your data, e.g. "liberal democrat". In addition, words with
domain specific meanings e.g. "party" meaning "political group", might
not be correctly classified in Wmatrix. Thirdly, some words may not be
known to the semantic tagger and therefore receive a Z99 tag
meaning 'unknown'. They will still receive a POS tag from the CLAWS
tagger.
There are two features in
Wmatrix that allow you to change the way that the system works:
- The "Domain tag wizard" allows you to give the semantic tagger
extra information about the semantic domains (or fields) if you know
in advance which domain(s) the text in your file is about. This will mean that the tagger
increases the likelihood of the preferred domain(s) and will usually
choose the tag(s) when an ambiguous word or MWE occurs in the text.
For example, the most
likely tag for "party" in Wmatrix is K1/S1.1.3+ to represent the celebration/entertainment
sense. The second most likely sense is G1.2 for political party. If you wish
to force the system to choose the political sense, then you can use the domain
tag wizard and enter "G", "G1" or "G1.2" in the 'preferred semantic field' box
when you load the data into Wmatrix.
Further instructions on this are contained in the "Domain tag wizard" screen.
You need to be using the advanced interface in order
to see this feature. Take the data prepared in tutorial A and run it through the domain
tag wizard using different 'preferred semantic fields' and see what effect they have.
- In order to add new words and MWEs to the USAS dictionaries
contained in Wmatrix, you can use the "My Tag Wizard" feature. This
allows you to create your own supplementary word list and MWE list
which you can then merge with the system dictionaries for your personal
use.
Running new data through "My Tag Wizard" rather than the normal tag
wizard activates these extended dictionaries for tagging. You could use
this feature to add new words or new senses of words that you have
found in your own data. Further instructions are contained in the "My
Tag Wizard" page within Wmatrix. You could also employ this wizard to
introduce a new semantic tag to the system by listing the words and
MWEs that you wish to be categorised with this tag. If you do that,
then bear in mind that the reference corpora (e.g. BNC sampler) are not
tagged with your new scheme, so comparability is an issue to take
account of. You need to be using the advanced Wmatrix interface in
order to have this feature available.
- Once you have created your own dictionaries to use in "My Tag Wizard",
you can still use the normal Wmatrix versions by returning to the plain
tag wizard and running new data through it.
- The following steps guide you through the process of creating a personal
lexicon to use in the My Tag Wizard feature:
- In order to find words that you might add to your supplementary dictionary,
you can look at the list of unknown words in each folder. The icon is a question
mark. If you click on it you will see a list of words that are not in the main
dictionaries of the semantic tagger. You will also see typos, mispelt words and
words that have been incorrectly tokenised by the system. For example,
in the Labour Manifesto for 2005, you will see items such as "full.They",
"globalisation", "G7"
and "G8". The first of these is caused by a lack of space character at the end of the
sentence between "full" and "They". Errors like this are due to the automatic way that the
PDF, DOC and RTF files were converted. You can manually correct them in the original text files and
reload them into Wmatrix if you wish, although it should be noted that they are very infrequent.
Words like "globalisation", "G7" and "G8" are good candidates to be added to your personal
dictionaries in the My Tag Wizard feature.
- Open a local file to store your personal lexicon and copy the appropriate lines from the unknown list into your file.
This local file should be in plain text format, so you should use WordPad or NotePad on Windows, TextEdit on MacOSx
or a plain text editor on Linux. If you use MSWord to edit it, then make sure that you save the
personal lexicon in plain text format.
For each line that you have copied, you will need to edit the semantic tag field.
For most of the lines in the list of unknown words, the semantic tag is shown as Z99.
However, for each of the unknown words, the USAS tagger within Wmatrix tries to make a best guess
at possible semantic categories. It looks up the unknown word in
WordNet to find a list of synonyms.
For each of these synonyms the tagger then looks them up in its dictionary. If the synonyms
occur in the USAS dictionary, then the semantic tags from the synonyms are used to make a candidate list
of tags for the unknown word. You may find that some or all of these candidate tags are not
appropriate so you can discard them.
If you are not sure which tag
to use, then read the guide to the semantic tagset
on the USAS web page.
You can also search the main dictionary for similar words and see how they are coded. To
do this, click on "USAS: Lexicon" in the Help menu. It is also worth viewing this file since you
will need to replicate the format in your own personal dictionary.
- In addition to unknown words, you can use the personal lexicon to override the tagging
of words that are already in the main system lexicon if the meanings tagged by the system are
incorrect for your data. You may notice these incorrect tags through frequency profiling
and concordancing on your data.
For example, the most
likely tag for "party" in Wmatrix is K1/S1.1.3+ to represent the celebration/entertainment
sense. The second most likely sense is G1.2 for political party. If you wish
to improve the chances of the system choosing the political sense, then you can copy the line
containing "party" from the
main system lexicon to your personal lexicon file and edit the order of the tags.
If you move G1.2 to be first in the semantic
tag list, it is much more likely to be chosen.
- You may also use the personal lexicon to introduce a completely new semantic tag for your data.
In the My Tag Wizard page, you will see example files which introduce a new tag 'I5' for
an innovation category. Bear in mind that new tags should follow the same format as existing ones,
i.e. an upper case letter followed by subcategories indicated by numbers.
- Once you are happy with your local copy of your personal lexicon, save it
to your local disk, then click on My Tag Wizard in
the tagging menu in Wmatrix. Follow the instructions there to create your personal dictionaries and
load the local copy of your lexicon to the system. Note that for My Tag Wizard to be activated you
need to load a personal MWE list (see steps below) or merge a blank MWE list. When it is activated you can test
running the Labour Manifesto through My Tag Wizard. Check that your personal lexicon changes have taken
effect in the tagging of the file.
- The following steps guide you through the process of creating a personal MWE list:
- Finding candidate MWEs for your data is more tricky than finding unknown words for the personal lexicon.
You may find items such as 'liberal democrat(s)' through the process of concordancing.
Another approach is to use the n-gram lists generated in step D.10 for extracting candidate phrases,
terms, or idioms for inclusion. Of course, you may known in advance names of people, organisations
or places that you wish to include.
- Editing a local copy of your personal MWE list is much the same as editing a local copy
of your personal lexicon. The main difference is the format of each line. There are two places to
view MWEs in the main system MWE list. Click on USAS MWEs in the Help menu to see the main system list.
There is also a sample file in the My Tag Wizard screen of new MWEs to be tagged as I5. To start off,
you can copy this format. Each part of the MWE should have "_*" which matches any POS tag. Later,
you can revise this if you wish the MWE entries to be tied more specifically to POS tags.
Each lines ends with a semantic tag or a list of semantic tags with the most likely one in
the first position.
- While you are editing your personal MWE list, you should check if similar entries already exist
in the main system MWE list, accessed as described above. If there are no similar entries,
then you can add a simple version of the new MWE containing "_*" for POS tags.
However, if a similar entry already exists, or you wish to override the tags for a particular MWE,
then you need to replicate the format in the main system entry.
Due to the way that the MWE templates in the system dictionary are written it is quite possible that
several 'match' at the same point in a given sentence.
Hence, a set of heuristics is applied by the semantic tagger to say which one should be chosen in such a case.
New personal rules may not be used because they are less tightly specified than those already in the system.
For example, if you create a new MWE entry:
going_* downhill_* M1
This overlaps with one already in the main system MWE list:
going_* {R*} downhill_RL A5.1-/A2.1
Since the 'downhill' part has a fixed POS tag "RL" the system rule wins over your new rule and is applied instead.
The way to fix this is to change your new rule to be
going_* {R*} downhill_RL M1
- Once you have finished editing the local copy of your personal MWE list, you should load it into the system
by clicking on My Tag Wizard and then the link for editing your personal dictionaries. Follow the instructions on
the screen to load the file.
Don't forget to merge both the personal lexicon and MWE list.
When that is complete, try running a new file through My Tag Wizard to see if your
new entries are being applied correctly.
Tutorial F: word collocations and semantic collocations
- This tutorial assumes that you have already completed tutorials A and B. You should also be using the advanced interface to Wmatrix.
If you're not using the advanced interface, switch to it now by clicking 'switch to advanced interface' at the top left of the Wmatrix screen.
- Enter the folder for the Labour manifesto (2005) that was uploaded to Wmatrix in tutorial B by clicking on the icon or the name.
- In the main table, you should see a column headed 'Collocation'. Underneath this will be two links called 'Word'
and 'Word-Semantic'.
- If you don't see these links, then scroll further down the table and locate the link called 'Calculate: word and semantic collocations' in the
manual operations and file conversions section
- Click on that calculate link and follow the instructions. The word level and semantic level collocations will now be calculated. You may need to
refresh the main folder view in Wmatrix while the collocations are being calculated. Once the calculations are completed, the links in the main table
will be activated.
- To view the word level collocations, click on the 'Word' link in the 'Collocation' column of the main table.
- You will see a table of all the collocates extracted from the Labour manifesto, for example "Sure Start", "Tony Blair" and "Preface Tony" are the first three.
- The default statistic used is the Multual Information (MI). You can change the statistic using the drop down box and clicking "Go". Eleven
different statistics are available for you to use. Select Log-Likelihood and click "Go".
- Using Log-Likelihood, you will see the first two collocates are "We will" and "per cent". This illustrates the difference between
collocates extracted using different statistics. For more information on the statistics used, please see the paper by Scott Piao:
Piao, S. (2002) Word alignment in English-Chinese parallel corpora.
Literary and linguistic computing, 17 (2), 207-230.
doi:10.1093/llc/17.2.207
- No matter which collocation statistic you use, the table of collocates will be ordered by the collocation statistic score itself.
A T-score filter is also applied to remove non-significant collocates.
- If you wish to find collocates of a given word, then enter the word in the 'search this list' box and click 'Go'. For example, using the MI
statistic, you can enter "health" in the search box and see that there are four collocates extracted: "mental health", "restored health",
"good health" and "health services"
- At any point, you can right-click on the save icon and download a tab-delimited file containing the information in the table.
This tab-delimited form can be imported into a spreadsheet or word-processor document.
- After using the search box, you must clear it and click 'Go' in order to see the full list of collocates again.
- You can use substrings in the search box. You will notice that entering 'school' will find collocates containing both
the singular and plural forms e.g. "primary schools" and "secondary school". A search for 'polic' will find "police officers"
and "neighbourhood policing" but also "International policy"
- To explore the semantic collocations, return to the Labour manifesto folder by clicking on the folder name at the top right of the Wmatrix window.
Then, click on 'Word-Semantic' in the Collocations column of the main table.
- The view of the list is very similar to the word collocations, but this time you can see which semantic tags are collocated with
certain words. For example, in the list for the MI statistic, "prime G1.1/S2mf" and "lawabiding N5+++c" are shown as the most significant
collocates.
- You can change the statistic and search the list as before with the word level collocations.
- You will need a list of semantic tags in order to see what groups of words are represented by these word-tag collocate pairs. You could open another
Wmatrix window and run concordances for the tags in order to see what sorts of words are being picked out.
- In the MI list, search on the word 'council'. You will see four semantic collocates: "council G1.1/I1", "councils S1.2.1-",
"councils S7.1+", and "councils A1.1.1".
- If you run concordances for the tag 'A1.1.1' and then search for the word 'councils' in the context,
you will see that this collocation represents 'councils' either tackling or dealing (tagged as A1.1.1) with antisocial behaviour, unauthorised sites or
pubs and clubs.
- If you run concordances for the tag 'S7.1+' and then search for the word 'councils' in the context,
you will see that this collocation represents 'councils' linked with words such as power, leading and organised (all tagged as S7.1+).
Read the wider concordance lines in order to see exactly what is written in the manifesto about this link.
- A similar search for the tag 'S1.2.1-' reveals that the word 'councils' is collocated with 'antisocial behaviour'.
- Carrying out the same operation for the tag 'G1.1/I1' shows the collocate 'council tax'.
- Using the word collocates and semantic collocates lists, you are now equipped to carry out a collocational analysis of the Labour
manifesto and compare it to the LibDem manifesto.
Tutorial G: metaphor analysis
- This tutorial provides pointers to more information for using Wmatrix for metaphor analysis. In the MELC project, we devised a number of new techniques including broad sweep to assist corpus researchers with metaphor analysis using semantic tags to find candidate source and target domains.
- For more detailed information on the process, please see the information and tutorial presented at a one day workshop in January 2014.
We have described our methods and results in multiple publications, in particular, please see:
Semino et al., 2018,
Semino et al., 2017,
Demmen et al., 2015.
- In order to access the broad sweep feature in Wmatrix, please use the following steps:
- Ensure that you are using Wmatrix version 5 onwards
- Ensure that you are using the advanced interface (see tutorials C and D for information on how to do this)
- In the "Options" menu, click on "Edit user options..."
- Find the option called "Broadsweep Features Toggle" and click the "Change" button to switch it on
- Broad sweep features will now be enabled in the "Word and USAS tag" frequency list and keyness analysis for semantic tags
- For any existing folders, you will need to click the option "Make: broad sweep frequencies" in the folder view
- For any new folders that you create via the tag wizard, the broad sweep frequencies will be calculated automatically while the feature is switched on
- If you wish, you can also disable the broadsweep features by toggling off the option again
Background reading
- Labour versus LibDem UK 2001 General Election:
Paul Rayson (2004).
Keywords are not enough.
Invited talk for JAECS (Japan Association for English Corpus Studies)
at Chuo University, Tokyo, Japan, 27th November 2004.
( slides)
slides)
- See section 4.4 of my PhD for a written account of the 2001 comparison:
Rayson, P. (2003).
Matrix: A statistical method and software tool for linguistic analysis through
corpus comparison.
Ph.D. thesis, Lancaster University.
(abstract or full text
 )
)