In addition, when all the manifestos are published you will be able to download crosstabs of word, POS and semantic tag frequencies with log-likelihood and dispersion statistics. These are tab delimited so can be opened in your favourite spreadsheet application.
| Conservatives | Labour | Liberal Democrats | Green Party | Plaid Cymru | Scottish National Party | Brexit Party | |
| Party website | www.conservatives.com | www.labour.org.uk | www.libdems.org.uk | www.greenparty.org.uk | www.plaid.cymru | www.snp.org | www.thebrexitparty.org |
| Launch date | 24 Nov 2019 | 21 Nov 2019 | 20 Nov 2019 | 19 Nov 2019 | 22 Nov 2019 | 27 Nov 2019 | 22 Nov 2019 |
| Direct link | |||||||
| Local copy | |||||||
| Edited text version | TXT | TXT | TXT | TXT | TXT | TXT | TXT |
| Number of words (tokens) | 20,106 | 24,798 | 26,163 | 22,695 | 16,747 | 21,061 | 1,883 |
| Number of unique words (types) | 3,572 | 4,401 | 4,401 | 4,115 | 3,965 | 3,438 | 775 |
| Word frequency list | TXT | TXT | TXT | TXT | TXT | TXT | TXT |
| Key word cloud | Figure 1 | Figure 3 | Figure 5 | Figure 7 | Figure 9 | Figure 11 | Figure 13 |
| Key semantic tag cloud | Figure 2 | Figure 4 | Figure 6 | Figure 8 | Figure 10 | Figure 12 | Figure 14 |
As in previous elections, I will make local copies of manifestos available since they often disappear offline after the election. To prepare the text versions, I will use Adobe Reader to save as text and then manually edit (using BBEdit) a small number of items such as headers, footers and page numbers to store them in pseudo-XML-style tags. In addition, I will follow the input format guidelines for CLAWS and convert n-dashes, pound signs, begin and end quotes to XML entities.
Notes:
1. I used the LibDems 'clear print' manifesto version since it was easier to convert to txt format.
2. Labour also have two other documents alongside their manifesto which I haven't included in the analysis: Funding real change and review of corporate tax relief.
A note on word counts: Wmatrix counts semantically meaningful multiword expressions (MWEs) as one item, so other corpus software may well provide different counts here. These figures also depend on tokenisation in our NLP pipeline (by CLAWS).
Word frequency lists are tab delimited so you can load them in to your favourite spreadsheet program. MWEs are shown in the word frequency lists as words connected by underscore characters.
Key word and semantic tag clouds are produced by comparing the data with the BNC Written Sampler corpus. The larger the font, the higher the log-likelihood score, so larger items are more significantly overused compared to the reference corpus. See the Wmatrix main page and online tutorials if you want more details about how this works.

Figure 1: Conservatives Key Word Cloud

Figure 2: Conservatives Key Semantic Tag Cloud
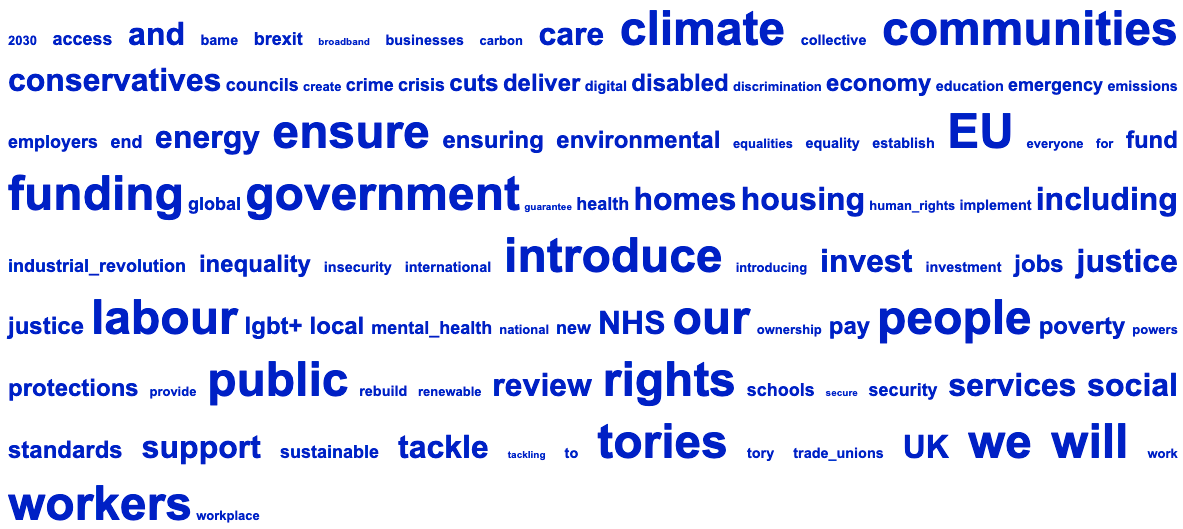
Figure 3: Labour Key Word Cloud

Figure 4: Labour Key Semantic Tag Cloud
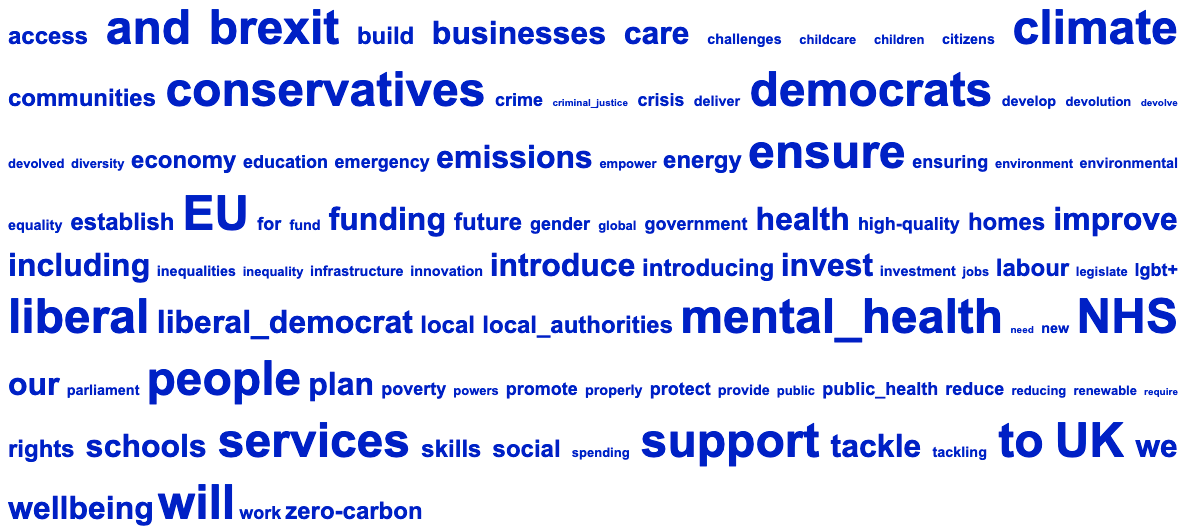
Figure 5: Liberal Democrats Key Word Cloud

Figure 6: Liberal Democrats Key Semantic Tag Cloud

Figure 7: Green Key Word Cloud

Figure 8: Green Key Semantic Tag Cloud

Figure 9: Plaid Cymru Key Word Cloud
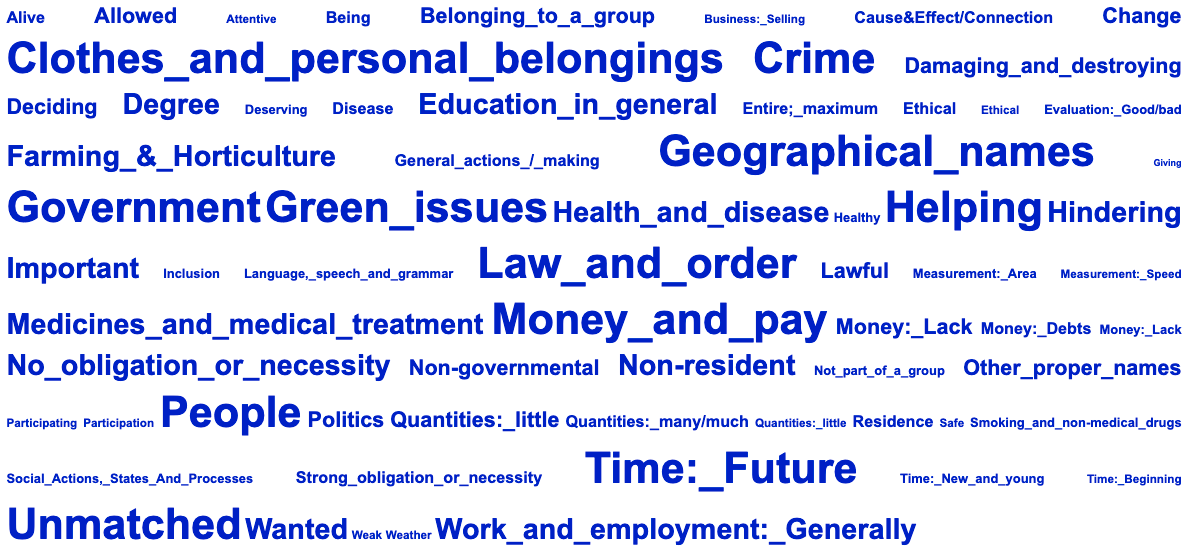
Figure 10: Plaid Cymru Key Semantic Tag Cloud

Figure 11: SNP Key Word Cloud

Figure 12: SNP Key Semantic Tag Cloud

Figure 13: Brexit Party Key Word Cloud

Figure 14: Brexit Party Key Semantic Tag Cloud