ACASD is a suite of programs for the automated semantic field tagging and content analysis of spontaneous spoken English. The system is made up of several separate software modules. The main constituents are a formatting pre-processor (TOSGML), the CLAWS part-of-speech tagger, a semantic tagger (SEMTAG), a syntactico-semantic linking system (MATRIX), and the statistics and retrieval package (SEMSTAT). All the programs are designed to run on a Sun Workstation (using Sun UNIX). Results from the retrieval package can be printed out, but the main feature for the end-user is the interactive nature of the retrieval process.
The system is being used by the market research company for commercial projects, so our aim is to make the system as robust as possible, i.e. so that any text you care to analyse would be processed. For this reason, our transcription guidelines are limited to producing raw text in normal orthographic form with a minimum of mark-up.
The software is used as an aid in preparing reports for market research clients based on a set of one-to-one non-directed interviews with members of the public selected for a given project. The results obtained are better than the normal tick-the-box interviews conducted to produce quantitative estimates about a particular product or service: the interviewee is not limited to answering a series of questions set in advance. The results are also an improvement on a qualitative survey which consists of a small number of non-directed interviews: here, the market researcher cannot hand-analyse enough text in a given limited time period to make quantitative jugdements about the product. We think our software gives the best of both worlds: quantitative estimates and the option of viewing the underlying text of the interviews.
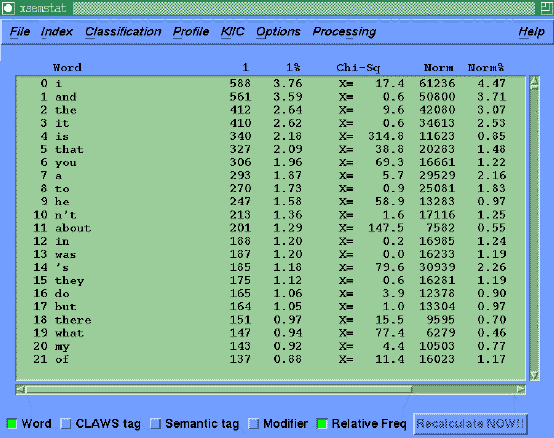
Once the text of the interviews has been processed to the SEMTAG stage, we can produce frequency profiles of semantic tags which highlight statistically significant items for further investigation, perhaps by concordance. The Chi-squared test is used to give a value to the words or tag frequencies which differ from a corpus-based norm value. We have collected nearly 3 million words of spoken data from people all over the country to produce these norms.
|
|
Corpus B was collected by Reflexions from 13 regions. 2 million words resulted from 797 interviewees, collected between January and June 1994, over 19 hall days. The interviews were non-directed, usually starting with the question "What's on your mind?". The idea was to collect a representative norm of English usage in a situation similar to that in which the product interviews are to be conducted. The people selected for interview form a balanced sample of age, gender, region (based on TV regions), and social class in a similar way to the demographic part of the British National Corpus (BNC). It is partly marked up for anaphoric reference.
<person age=59 sex=f type=C1 Region=Birmingham Interviewer=Judy Origin=Midlands/Central> <question> Can we start off by just talking about what's on your mind? <r> Now? <q> Anything you want to talk about. <r> Well my holidays, yes, and what I did this week and whether it's going to pour down with rain, it looks like it.Each interview is headed by an SGML (Standard Generalised Mark-up Language) tag (the text inside angled brackets). We normally record age, gender, social class, region, the interviewer's name and a rough idea of the origin of the interviewee. In fact any attribute can be recorded in the same format. The header information is used by the retrieval software to split the data under analysis and produce sub-corpora if required.
We mark questions and answers so that the interviewers' language can be omitted from the analysis but included in any concordances produced.
E - EMOTIONAL ACTIONS, STATES AND PROCESSES
1 General
2 Liking
3 Calm/Violent/Angry
4 Happy/sad: 1 Happy
2 Contentment
5 Fear/bravery/shock
6 Worry, concern, confident
H - ARCHITECTURE, BUILDINGS, HOUSES AND THE HOME
1 Architecture and kinds of houses and buildings
2 Parts of buildings
3 Areas around or near houses
4 Residence
5 Furniture and household fittings
L - LIFE AND LIVING THINGS
1 Life and living things
2 Living creatures generally
3 Plants
Antonyms are identified using +/- markers. So, for example, happy
would usually be tagged E4.1+ and sad would be tagged
E4.1-.
We have a lexicon of over 36,000 grammatical words (i.e. word and part-of-speech), and an idiom list with over 15,000 entries. The idioms are phrases like all in all, art nouveau, and have a screw loose, to which we assign a single semantic tag.
We apply the following set of disambiguation techniques:
SEMSTAT first displays ACASD data as a semantic tag frequency profile. The user can interactively change the view they see to include other fields such as word, POS tag, linked words (from MATRIX) and relative frequency.
Each line in a profile displays a Chi-squared value that shows which items
differ significantly from an expected frequency derived from the normative
corpora.
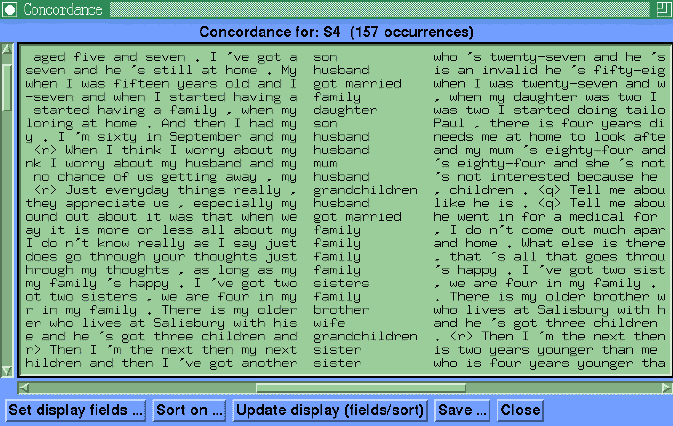
Within any view the user can double click on the profile to see a
concordance of the selected item. It is also possible to display other fields
in the concordance window so that the user can see patterns of tagging
surrounding a key item.
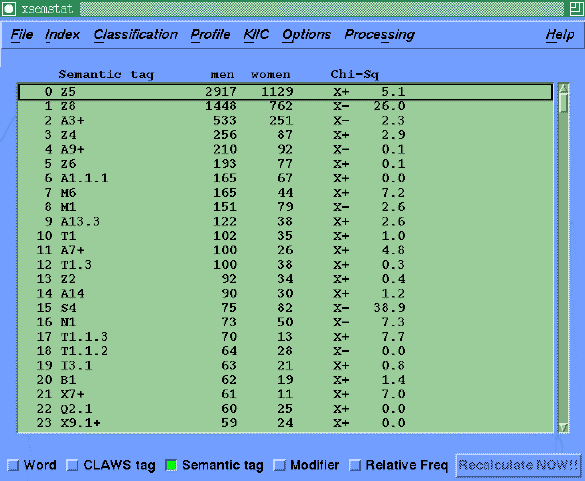
Using a classification scheme based on the information encoded in the
file headers a user can select subcorpora and hide parts of the text
not of interest (for example the interviewers questions).
The scheme also allows the user to display frequencies for different parts
of the corpus alongside each other. The Chi-squared value is then used
to show items whose frequency distribution across the subcorpora
is statistically significant.
0000001 001 **88;0;person 01 NULL 0000003 001 <question> 01 NULL 0000003 002 ---------------------------------------------------- 0000003 010 Can 03 [VM/100] NN1%/0 VV0%/0 0000003 020 we 03 PPIS2 0000003 030 start 98 VVI 0000003 040 off 97 RP 0000003 050 by 03 [II/99] RP%/1 0000003 060 just 03 [RR/94] JJ@/6 0000003 070 talking 03 [VVG/92] NN1@/5 JJ@/3 0000003 080 about 99 II 0000003 090 what > 03 DDQ 0000003 091 's < 97 VBZ 0000003 100 on 03 [II/96] RP@/4 0000003 110 your 03 APPGE 0000003 120 mind 03 [NN1/100] VV0/0 0000003 121 ? 03 ?and horizontal files, usually word_tag sequences, possibly including skeleton parsing (as in the corpora AP, Hansard, etc):
F001 1 v [N A_AT1 21-year-old_JB Rockland_NP1 man_NN1 N][V drowned_VVD [Fa while_CS [V swimming_VVG [P in_II [N an_AT1 abandoned_JJ [ limestone_NN1 quarry_NN1 ][P in_II [N this_DD1 coastal_JJ city_NNL1 N] P]N]P]V]Fa]V] ._.and raw text:
<question> Can we start off by just talking about what's on your mind?and BNC files:
<s n=001> <w ITJ>Yeah <w UNC>erm <pause> <w AT0>the <w AJ0>other <w UNC>er <pause> <w NN1>aspect <w PRF>of <w DT0>any <w NN1>discussion <w PRF>of <w NP0>Vienna<pause> <w VBZ>is <w AT0>the <w UNC>er<c PUN>, <w VBZ>is <w NN1>discussion <w PRF>of <w AT0>the <w NN0>congress <w NN1>system <w PNX>itself<c PUN>.In this case SEMSTAT retrieves personal details from the header of each file. This means that BNC files can be analysed on the basis of individual speakers not just respondents as before.
We are currently using SEMSTAT to compare native and non-native speakers of English in Sylviane Granger's ICLE (International Corpus of Learner English) corpus.
The system has other potential applications in linguistics and more generally in the social sciences and humanities: for example, a pilot study of a large corpus of doctor-patient interactions has been carried out using ACASD (see Thomas and Wilson, 1996), and its application to the stylistic analysis of written as well as spoken English has been piloted by Wilson and Leech (1993).