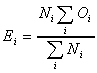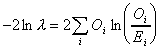17. It must be borne in mind that these are simply variant spellings of
the same word, and may have been somewhat unreliably transcribed, on
the basis of limited phonetic evidence. On the other hand, the result,
in terms of differentiation between the age-groups, is so marked that
it must reflect a real difference of linguistic behaviour.
References
Biber, D. (1988). Variation Across Speech and Writing.
Cambridge University Press.
Burnard, L. (compiler)(1995), The Users Reference Guide
for the British National Corpus. Oxford: Oxford University
Computing Services.
Carroll, J.B., Davies, P., and Richman, B. (1971). The
American Heritage Word Frequency Book. Houghton Mifflin Company,
Boston.
Coates, J. (1986). Women, Men and Language. London,
Longman. 114-117
Crowdy, S. (1993), 'Spoken corpus design and transcription',
Literary and Linguistic Computing, 8(4), 259-265.
Crowdy, S. (1995), 'The BNC Spoken Corpus', in G. Leech,
G. Myers and J. Thomas (eds.), Spoken English on Computer:
Transcription, Mark-up and Application, London: Longman, 224-234.
Dunning, Ted. (1993). 'Accurate methods for the statistics
of surprise and coincidence' Computational Linguistics,
Volume 19, number 1, 61-74.
Francis, W.N., and Kucera, H. (1982). Frequency
Analysis of English Usage: Lexicon and Grammar. Houghton Mifflin
Company, Boston.
Hirschman, L (1994) 'Female-male differences in
conversational interaction', Language in Society 23, 427-442
Hudson, R. A.. (1994), 'About 37% of word-tokens are nouns',
Language, 70, 331-339.
Lakoff, R. (1975) Language and Woman's Place. New
York: Harper and Row.
Tannen, D. (1991), You Just Don't Understand: Women
and Men in Conversation. London: Virago Press. 76-77
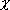 2 value of
difference between different sectors of the corpus according to
gender, age and social group. A fourth variable, that of geographical
region of the United Kingdom, is not investigated in this article,
although it remains a promising subject for future research. (As
background we also briefly examine differences between spoken
and written material in the British National Corpus (BNC).) This
study is illustrative of the potentiality of the Conversational
Corpus for future corpus-based research on social differentiation
in the use of language. There are evident limitations, including
(a) the reliance on vocabulary frequency lists, and (b) the simplicity
of the transcription system employed for the spoken part of the
BNC. The conclusion of the article considers future advances in
the research paradigm illustrated here.
2 value of
difference between different sectors of the corpus according to
gender, age and social group. A fourth variable, that of geographical
region of the United Kingdom, is not investigated in this article,
although it remains a promising subject for future research. (As
background we also briefly examine differences between spoken
and written material in the British National Corpus (BNC).) This
study is illustrative of the potentiality of the Conversational
Corpus for future corpus-based research on social differentiation
in the use of language. There are evident limitations, including
(a) the reliance on vocabulary frequency lists, and (b) the simplicity
of the transcription system employed for the spoken part of the
BNC. The conclusion of the article considers future advances in
the research paradigm illustrated here.
 where
where