Log-likelihood and effect size calculator
To use this wizard, type in frequencies for one word
and the corpus sizes and press the calculate button.
Notes:
1. Please enter plain numbers without commas
(or other non-numeric characters) as they will confuse the
calculator!
2. The LL wizard shows a plus or minus symbol before the log-likelihood value
to indicate overuse or underuse respectively in corpus 1 relative to corpus 2.
3. The log-likelihood value itself is always a positive number. However, my script compares
relative frequencies between the two corpora in order to insert an indicator for
'+' overuse and '-' underuse of corpus 1 relative to corpus 2.
|
How to calculate log likelihood
Log likelihood is calculated by constructing a contingency table as follows:
| Corpus 1 | Corpus 2 | Total |
| Frequency of word | a | b | a+b |
| Frequency of other words | c-a | d-b | c+d-a-b |
| Total | c | d | c+d |
Note that the value 'c' corresponds to the number of words in corpus
one, and 'd' corresponds to the number of words in corpus two (N
values). The values 'a' and 'b' are called the observed values (O),
whereas we need to calculate the expected values (E) according to the
following formula:
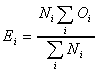
In our case N1 = c, and N2 = d. So, for this word, E1 = c*(a+b) / (c+d)
and E2 = d*(a+b) / (c+d). The calculation for the expected values takes
account of the size of the two corpora, so we do not need to
normalize the figures before applying the formula. We can then
calculate the log-likelihood value according to this formula:
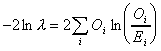
This equates to calculating log-likelihood G2 as follows:
G2 = 2*((a*ln (a/E1)) + (b*ln (b/E2)))
Note 1: (thanks to Stefan Th. Gries) The form of the log-likelihood
calculation that I use comes from the Read and Cressie research cited in
Rayson and Garside (2000) rather than the form derived in Dunning (1993).
Note 2: (thanks to Chris Brew)
To form the log-likelihood, we calculate the sum over terms of the form
x*ln(x/E). For strictly positive x it is easy to compute these terms,
while if x is zero ln(x/E) will be negative infinity.
However the limit
of x*ln(x) as x goes to zero is still zero, so when summing we can just
ignore cells where x = 0.
Calculating ln(0) returns an error in, for example,
MSExcel and the C-maths library.
The higher the G2 value, the more significant is the difference between
two frequency scores. For these tables, a G2 of 3.8 or higher is
significant at the level of p < 0.05 and a G2 of 6.6 or higher is
significant at p < 0.01.
- 95th percentile; 5% level; p < 0.05; critical value = 3.84
- 99th percentile; 1% level; p < 0.01; critical value = 6.63
- 99.9th percentile; 0.1% level; p < 0.001; critical value = 10.83
- 99.99th percentile; 0.01% level; p < 0.0001; critical value = 15.13
Effect size calculations
Alongside the Log Likelihood measure, the following effect size measures are implemented on this page:
- %DIFF - see Gabrielatos and Marchi (2012)
Costas has also provided an FAQ with more details
- Bayes Factor (BIC) - see Wilson (2013)
You can interpret the approximate Bayes Factor as degrees of evidence against the null hypothesis as follows:
0-2: not worth more than a bare mention
2-6: positive evidence against H0
6-10: strong evidence against H0
> 10: very strong evidence against H0
For negative scores, the scale is read as "in favour of" instead of "against" (Wilson, personal communication).
- Effect Size for Log Likelihood (ELL) - see Johnston et al (2006)
ELL varies between 0 and 1 (inclusive). Johnston et al. say "interpretation is straightforward as the proportion of the maximum departure between
the observed and expected proportions".
- Relative Risk - see links below
- Log Ratio - see Andrew Hardie's CASS blog for how to interpret this
Note that if either word has zero frequency then a small adjustment is automatically applied (0.5 observed frequency
which is then normalised) to avoid division by zero errors.
- Odds Ratio - see links below
Further reading
For a detailed comparison of the log-likelihood and chi-squared statistics, see
Rayson P., Berridge D. and Francis B. (2004).
Extending the Cochran rule for the comparison of word frequencies between corpora.
In Volume II of Purnelle G., Fairon C., Dister A. (eds.)
Le poids des mots: Proceedings of the 7th International Conference on
Statistical analysis of textual data
(JADT 2004), Louvain-la-Neuve, Belgium, March 10-12, 2004,
Presses universitaires de Louvain, pp. 926 - 936. ISBN 2-930344-50-4.

The log-likelihood test can be used for corpus comparison. See
Rayson, P. and Garside, R. (2000).
Comparing corpora using frequency profiling.
In proceedings of the workshop on
Comparing Corpora,
held in conjunction with the 38th annual meeting of the Association for Computational Linguistics
(ACL 2000).
1-8 October 2000, Hong Kong, pp. 1 - 6.
For a more detailed review of various statistics, see:
Rayson, P. (2003).
Matrix: A statistical method and software tool for linguistic analysis through
corpus comparison.
Ph.D. thesis, Lancaster University.
And to read more about the use of log-likelihood with tag-level comparisons, see:
Rayson, P. (2008).
From key words to key semantic domains.
International Journal of Corpus Linguistics.
13:4 pp. 519-549.
DOI: 10.1075/ijcl.13.4.06ray
The chi-square distribution calculator (Stat Trek)
makes it easy to compute
cumulative probabilities, based on the chi-square statistic.
The Institute of Phonetic Sciences in Amsterdam, have a similar calculator.
Also see Dunning, Ted. (1993).
Accurate Methods for the Statistics of Surprise and Coincidence.
Computational Linguistics, Volume 19, number 1, pp. 61-74.
(pdf)
Andrew Hardie has created a
significance test system
which calculates Chi-squared, log-likelihood and the Fisher Exact Test
for contingency tables using R.
There is an increasing movement in corpus linguistics and other fields
(e.g. Psychology)
to move away from null hypothesis testing and p-values,
and to calculate effect size measures as well as significance values.
For a discussion of these measures and why we need them,
see the following resources,
presentations and publications:
- CEP932 effect size content
which discusses measures including Cohen's d, Pearson r Correlation coefficient and the Odds Ratio
- Vaclav Brezina (2014) Effect sizes in corpus linguistics:
keywords, collocations and diachronic comparison.
Presented at the ICAME 2014 conference, University of Nottingham.
[Vaclav uses Cohen's D as an effect size measure.]
- Effect size for Chi-square test
which describes measures such as Phi, Cramer's V,
Odds ratio and
Relative risk
- Statistics for Psychology's explanation of
Null hypothesis testing and effect sizes which, for example, states
"If a small difference between two groups' means is not signficant when I test 100 people, should I suddenly get excited about exactly the same difference if, after testing 1000 people, I find it is now significant?"
- Gries, Stefan Th. (2014)
Frequency tables, effect sizes, and explorations.
In Dylan Glynn & Justyna Robinson (eds.), Corpus methods for semantics: quantitative studies in polysemy and synonymy, 365-389. Amsterdam & Philadelphia: John Benjamins.
[In this paper, Stefan uses effect size measures Phi, Odds Ratio for 2 x 2 tables and Cramer's V for larger r-by-c tables.]
- Andrew Hardie's Log Ratio
which is in fact the binary log of the relative risk, and can only apply to
2 x 2 tables along with the Odds Ratio.
- Johnston, J.E., Berry, K.J. and Mielke, P.W. (2006)
Measures of effect size for chi-squared and likelihood-ratio goodness-of-fit tests.
Perceptual and Motor Skills: Volume 103, Issue , pp. 412-414.
DOI: 10.2466/pms.103.2.412-414
[This presents an effect size measure applicable to Log-likelihood.]
- Kuhberger A, Fritz A, Scherndl T (2014)
Publication Bias in Psychology: A Diagnosis Based on the Correlation between Effect Size and Sample Size.
PLoS ONE 9(9): e105825. doi:10.1371/journal.pone.0105825
- Jeffrey T. Leek and Roger D. Peng (2015)
Statistics: P values are just the tip of the iceberg
Nature 520, 612 (30 April 2015) doi:10.1038/520612a
[This paper urges us not to just focus on the statistics: "Statisticians and the people they teach and collaborate with need to stop arguing about P values, and prevent the rest of the iceberg from sinking science."]
- Donald Sharpe (2015)
Your Chi-Square Test is Statistically Significant: Now What?
Practical Assessment, Research & Evaluation. Volume 20, Number 8, April 2015.
- Scott Weingart's 2013 blog on
Friends don't let friends calculate p-values (without fully understanding them)
- Sean Wallis' blog and paper about
Measures of association for contingency tables
- Cumming, G. (2014)
The New Statistics: Why and How.
Psychological Science. 25(1), pp. 7-29.
DOI: 10.1177/0956797613504966
[Mentions that Cohen's D is widely used but has pitfalls.]
- Gabrielatos, C. and Marchi, A. (2012)
Keyness: Appropriate metrics and practical issues.
CADS International Conference 2012. Corpus-assisted Discourse Studies: More than the sum of Discourse Analysis and computing?, 13-14 September, University of Bologna, Italy.
[Presents the %DIFF effect size measure which Costas and Anna argue should be applied to pairwise corpus comparisons to calculate keyness.]
- Gries, Stefan Th. (2005)
Null-hypothesis significance testing of word frequencies: a follow-up on Kilgarriff.
Corpus Linguistics and Linguistic Theory 1(2). 277-294.
[Stefan compares chi-square, p-values, Cramer's V, Cohen's d, and d*, along with
Bonferroni and Holm's corrections for post-hoc testing.]
There are a number of other papers related to the use of significance testing,
keyness statistics and corpus comparison, e.g.
Kilgarriff (2005),
Paquot and Bestgen (2009),
Baron et al. (2009),
Wilson (2013)
and
Lijffijt et al.
Downloadable spreadsheet
I've made a spreadsheet incorporating the log-likelihood calculation and the set of effect size measures:
SigEff.xlsx (last updated 4th July 2016). This would be useful if you want to calculate a large
number of results from pre-existing datasets.
The effect sizes are all implemented for the 2 x 2 case, but only Bayes Factor and ELL are implemented for the general R x C case,
because %DIFF, Relative Risk, Log Ratio and Odds Ratio are only applicable to pairwise comparisons.
If you have technical problems please get in touch with
Paul Rayson
|